
While th e previous post in this series described how to remove duplicate values in Excel, this post describes how to identify duplicates.
e previous post in this series described how to remove duplicate values in Excel, this post describes how to identify duplicates.
The remove duplicates function doesn’t tell you which values are duplicates, it just removes them. Sometimes you need a list of the duplicates so you can review them in detail or include them in your workpapers.
So we’ll look at how to create a list of duplicates across all values/columns and in specific columns.
These procedures are written for Excel 2013, but the same steps should also work in Excel 2010, but the screenshots might be a little different.
Identifying Duplicates Across All Columns
To identify duplicates across all values (columns) in an Excel table:
- Highlight all the cells that you want to analyze.
In Example 1 below, I selected all cells in the table (to enlarge an example, click it). To highlight the table, click in cell A1, and while holding the mouse button, drag down to cell D11. Release the mouse button.
- On the Home tab, click the following: Conditional Formatting, Highlight Cell Rules, Duplicate Values.
See Example 1 below.
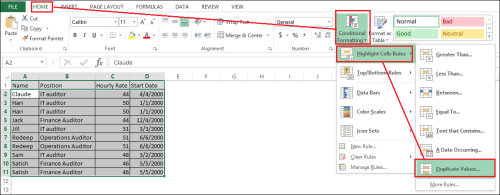
Example 1
- The Duplicate Values dialog box appears, and the duplicates in each column are highlighted immediately. Accept the default values, and press OK.
See Example 2 below.
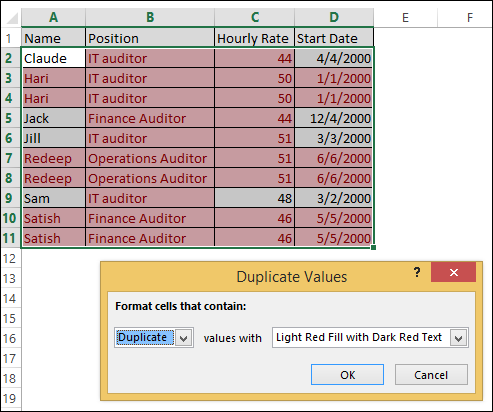
Example 2
- Notice the following in Example 2 above:
– In column A, Hari, Redeep, and Satish are the only duplicate names (red). Claude, Jack, Jill, and Sam (grey) are unique values.
– In column B, all the values are red, and no unique values exist.
– In column C, the only unique value is 48 (grey)
– In column D, 4 dates are unique (grey) and the rest are duplicates (red). - To list the rows that contain duplicate values across all columns, you have to filter the values. This is a 3-step process.
First, position the cursor in row 1; when the cursor changes to an arrow, click once to highlight the entire row.
See Example 3 below.
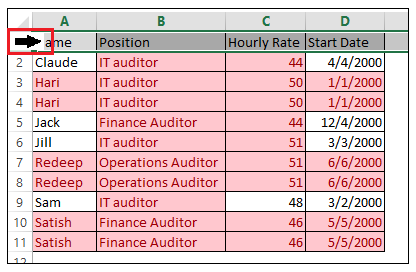
Example 3
- Second, apply the filter arrows to the columns: in the Data tab, click Filter.
See Example 4 below (the filter arrows don’t appear until after this step–see Example 5 further down).
Example 4
- Third, in column A, click the filter arrow, Filter by Color, and then the light red color (which identifies duplicate values) under Filter by Cell Color.
See Example 5 below.
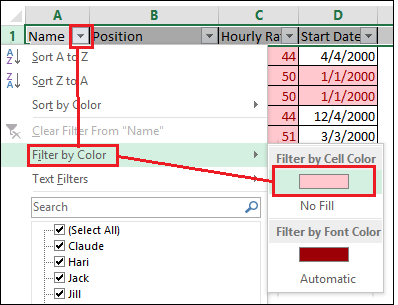
Example 5
- The result is a list of duplicates across all columns.
This is the list that you can save in your workpaper.
See Example 6 below.
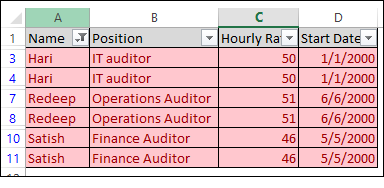
Example 6






One Important Note
Because of how this Excel function works, be careful if any cell in one column contains data that is identical to the data in another column.
For example, assume we have a table similar to Example 3 in step 5 above, except that it contains “Jill” in cell B9 (which is identical to the value in cell A6). When you analyze this table, ‘Jill’ will be flagged as a duplicate in both places. See red boxes in Example 3a below.

Example 3a
When you filter this table for duplicates across all cells, you get the result shown below in Example 3b below. The fact that cell D6 (3/3/2000) is white tells you something is not right.

Example 3b
However, by looking at the original data (Example 3a above), it’s clear that the two rows containing Jill are NOT duplicates of each other. Therefore, row 6 can be safely filtered out (in column D, use the filter to deselect 3/3/2000 so that the entire row is hidden).
The result is a correct listing of duplicates across all columns, shown in Example 3c below.

Example 3c
Keep in mind that this example is a little obvious, as values like ‘Jill’ would not normally appear in a column named Position.
However, if you have a table that contains columns called First Name and Last Name, that could be more of a challenge. If ‘Simon’ was one person’s first name and another person’s last name (which is not uncommon in the USA), you’d have the same condition, and that would be easier to miss when you analyze for duplicates.
I don’t think this issue will occur very often, and when it does, you can catch it by noticing values that are not shaded light red. So in conclusion, I still think using this Excel function to identify duplicates is a good one.
But be careful out there, and always check your results.
A shout-out to John, who raised this question in the comments. Thanks!
See all the posts for these series at Excel: Basic Data Analytic series.

Thanks, sorry about my vague post on your last entry. This is exactly what I was referring to. I wish the “Remove” duplicates tool was a Duplicates tool, giving me options to delete, export, or highlight the results.
I’ve used highlighting rules before but never this method. Only because, I didn’t realize there was a predefined auto rule. I usually build a countifs rules.
I do have one question.
From the auto highlight rule, what happens if the word Jill appeared in cell B9 of your Example 3. Would A6 highlight as well?
Thanks for your time, this is a great blog.
LikeLike
John,
Thanks for clarifying.
Excellent question. Strangely enough, the answer is yes. Since A6 and B9 would both contain “Jill”, both would be identified as duplicates.
In the example above, we are trying to determine which rows have duplicate columns across all columns, not which CELLS have a duplicate across all rows.
In my mind, it should not work that way because A6 and B9 are in separate columns. I wonder if that’s a bug. I’ll see what I can find out….
Update: doesn’t look like a bug. I added ‘One Important Note’ above based on your excellent comment. Thanks!
Glad you like the blog. Please spread the word.
LikeLike
Hi,
You’d need to highlight column A only before using the duplicate formatting. Basically the duplicate formatting compares every single cell within the highlighted area, and not just comparing rows alone.
LikeLike
Mysticeti,
That’s true if you only want to compare values in a single column. In the post above, I’m comparing the values across all columns to determine if any entire row is the same values as any other entire row.
Thanks for the input.
LikeLike
I think, Mysticeti is correct. You would need to highlight only column 1, apply the formatting rule, highlight column 2, apply the rule again… through each column. It still leaves you needing to apply the color filter to each column. [actually I think there is a gotcha in this] Depending upon how large the table is this method may be the quickest so long as you can visually confirm the duplicates. However, I think the row [ JILL | Operations Auditor | 44 | 1/1/2000 ] would falsely flag as a duplicate.
I noted I use countifs. In the example above I would have added a column with the formula = Trim(A2)&”:”&Trim(B2)&”:”&Trim(C2)&”:”Trim(D2) fill down the remaining column E cells. Highlight A2:D11 and apply a formula condition “= 1 < COUNTIF($E2, $E$2:$E$11)". This would highlight the whole row.
I'm still very happy to see the autorule. I think it will make things easier. And would also help identify near duplicates. Which are often just as problematic and harder to find.
LikeLike
John,
I think you’re right, but haven’t tried it yet. I see I missed Mysticeti’s original meaning in his comment. I think I’ll add a note above that you need to ensure that all values need to be unique.
You don’t want to know what I used to do before someone showed me this autorule method…
I’m trying to keep this simple, which is why I like the autorule. But it has its downsides.
Thanks so much for the info!
LikeLike
Hey Mack –
Shane (my buddy at r3s) worked at a MS consultancy for years and is a certified excel ninja (Microsoft Certified Application Specialist (MSCS) in Excel). You guys should pick eachother’s brain if you find any bugs you can’t figure out immediately as you work through this post series. He’s one of the best excel guys I’ve ever seen. Just wanted to throw that resource out there.
Thanks again for the great posts.
LikeLike
Christian,
Thanks, that’s good to know!
LikeLike
I have a spreadsheet of NFL teams for a pool I run. Column A is the list of names and columns B – R are the weeks in the season. Each week participants pick a team but they can’t repeat a team in any week over the course of the season. For instance, “John” in cell A1 might have: NE, DEN, SF, NO as his selections in weeks 1-4 (cells B1 – B4). If John entered NE for week 5, I would like it to be identified as a duplicate. Similarly, any duplicates for all of the other participants would need to be identified. I can highlight each row and then do “Conditional Formatting, Highlight Cell Rules, Duplicate Values” which works but I have to do each row one at a time and there are several hundred rows. If I select all rows and do the same Conditional Formatting, it identifies all duplicates across the whole spreadsheet, which is incorrect (For instance, John has NE, DEN, SF, NO in row 1 and Jim has NYG, MIA, NE, ATL in row 2. Applying conditional formatting to the whole spreadsheet would incorrectly highlight NE as a duplicate even though different participants have entered the picks). Is there a way to do this either with Conditional Formatting or with a formula? Thanks in advance for your help!
LikeLike
My suggestion. Use a formula condition not duplicates. Select B2:R#, select “conditional formatting/New Rule/use formula… with the following formula “=CountIF($B2:$R2,B2)>1” Pick the color you want the cell to be.
LikeLike
I didn’t try John’s solution, but it looks good.
If it works, let us know….
LikeLike
That works! Thanks so much.
LikeLike
I’m trying to come up with a formula to sum the records of teams over the course of a season. Column A is team names, Column B is the weekly records, with ties also a possibility (so B2 could be 10-4, B3 could be 7-6-1, B4 could be 3-11, etc). So, in this case with only three teams, I would want B5 to contain a formula that totals the records of all three teams and displays the cumulative total as 20-21-1. I could also display the 10-4 record in B2 as 10-4-0 and the 3-11 record as 3-11-0 if that makes it easier. Any help would be appreciated. Thank you!
LikeLike
Helper Columns: The easiest way to do this would be to split the cell into 3 separate columns and sum them individually and then rebuild your record. If you really must do this in a single formula, an array formula might do it (not my thing), but I believe you are looking at building a VBA function which may be a stretch based on your questions so far. Totally doable and a great intro to programming, but you will have to program. You might find more people with that sort of experience at Mr. Excel or OzGrid (my rec not necessarily this sites rec).
LikeLike
John,
Thanks for your input. I recommend Mr Excel and use it all the time.
Never heard of OzGrid; I’ll have to check it out.
LikeLike
Thank you John!
LikeLike
So I tried the formula below and it works fine for the wins but the losses always are totaling to zero. Do you see what might be wrong with the losses side? Thanks again!
=SUMPRODUCT(LEFT(0&B2:B10,FIND(“-“,B2:B10&”-“))+0)&”-“&SUMPRODUCT(MID(B2:B10,FIND(“-“,B2:B10&”-“)+1,2))
LikeLike
Try
=SUMPRODUCT(LEFT(0&B2:B10,FIND(“-“,B2:B10&”-“))+0)&”-“&SUMPRODUCT(Value(MID(B2:B10,FIND(“-“,B2:B10&”-“)+1,2)))
Mid returns a text formatted element. Technically you should do the same with Left. Excel gracefully allows you to “+0” for the left you might have been able to do the same with mid but technically you should use value().
LikeLike
=SUMPRODUCT(LEFT(B2:B10,FIND(“-“,B2:B10))+0)&”-“&SUMPRODUCT(Value(MID(B2:B10,FIND(“-“,B2:B10)+1,2)))
I’m also not sure where you got all the extra 0& or &”-“‘s from but this is cleaner. I also confirmed you could replace the Value() and post pended Mid() with a +0, either would have worked.
LikeLike
Thanks John. Unfortunately, those didn’t work for me as I get a “#NAME?” error when using either. It worked for you?
LikeLike
Jonathan,
It did work for me. This is somewhat off the rails from the original post PM me with your workbook jtjenkins@shaw.ca. I’ll have a look over the weekend, I’ve built a few draft workbooks over the years.
LikeLike
I appreciate you guys working together! Glad the blog brought you together.
LikeLike